A Fun Try into Building an Integrated Research Environment
Where and how it begins
The genesis of this endeavor sprouted a couple of years back when I found myself in various research projects, craving efficiency and scalability. The repetitive tasks of data cleansing and performance tracking began to weigh heavy, making me wonder: could there be a more streamlined approach?
Of course, I didn’t set out to develop a universally optimized system to fit all investment research needs. Each research project comes with its own unique demands, rendering such an ambition impractical, especially as a personal hoby.
Instead, my aim was to create a lightweight version that distilled common elements across the diverse projects that gain my interest. The vision? A system where frequently used models, data sources, and update processes could be neatly organized into modules for easy reuse. Thus, when inspiration struck, I could swiftly translate it into a calculation unit leveraging existing tools, deploying it for historical data updates and ongoing performance monitoring—a typical iteration in a research project.
How it is for the moment
To me, the crux of achieving this goal lies in abstraction and modularization—distilling reusable calculations and processes into manageable units. This vision has largely materialized through the following design and implementation.
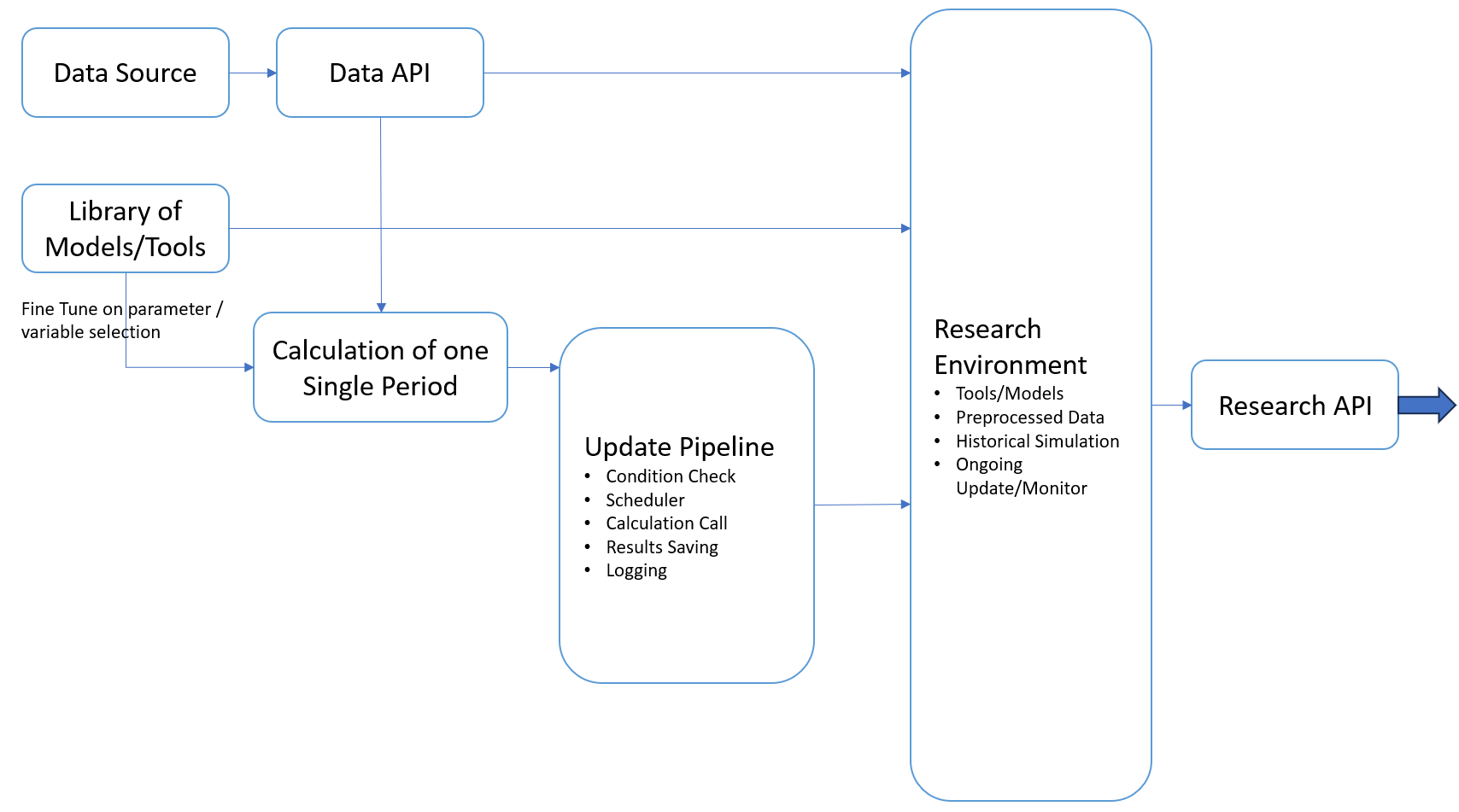
The development of this environment seamlessly intertwined with ongoing research projects. Often, it merely required an extra step beyond project requirements. For instance, when delving into portfolio construction models, common elements like matrix operations and convex optimization were recurrent. Rather than treating them as isolated instances, I invested time in abstracting them into reusable functions or classes within organized packages. This exercise drastically reduces future efforts when similar topics resurface.
Following this train of thought, when integrating data from new sources, I would always prefer building standardized APIs to deliver data in a consistent format. Although this approach demands additional time initially, the long-term benefits are immense. These APIs become versatile tools, usable across various scenarios, from one-time research tasks to ongoing monitoring, thus fostering an integrated research environment with aligned inputs.
The culmination of such abstractions comprises the first two components of my research environment: the Data API and Libraries of Models and Tools. Together, these modules fulfill the initial half of my goal—enabling the reuse of previous code to accelerate the implementation of new ideas. Now, attention shifts to the latter half: applying relevant calculations to common scenarios (e.g., historical and ongoing monitoring) with an automated data update pipeline.
Initially, this task seemed daunting. WWhat sort of data update pipeline could support all kinds of data processes, potentially spanning macroeconomic, accounting, and pricing data? Let alone for the steps of verifying the need for calculation, carrying on the calculation, logging and validatig? Soon I realized that regardless of the underlying models, most calculations could be abstracted into a series of units dependent on each other. These units are designed to identify timestamps or events for potential calculation, verify necessary conditions such as upstream data source availability, trigger the calculation if desired, and log the calculation’s completeness and validation.
And More..
More or less, this is the investment research environment I’ve envisioned.
Over the past couple of years, I’ve dedicated intermittent time to developing this system. Gotta to say that there’s a unique satisfaction in the development process, distinct from research. In research, the thrill often stems from understanding or finding a solution. In contrast, the satisfaction of development grows gradually. With each line of code, I inch closer to realizing this vision.
This environment has proven invaluable in my research, saving a great deal of repetitive exercises and allowing me to focus on the more enjoyable aspects. For example, one specific instance of its application is in supporting bottom-up portfolio strategies.
In the Data API, diverse data sources are wrapped within standardized modules and functions to yield aligned outputs. Here, special attention is paid to avoid lookahead bias, ensuring data is used appropriately in historical simulations after its release. Additionally, common data cleaning and merging methods—such as accounting statement preprocessing and calendar handling—are incorporated to expedite further data manipulation and usage across diverse applications.
Similarly, frequently used low-level calculations (e.g., numerical methods, statistical procedures) and high-level models (e.g., nowcasting, alpha model, portfolio construction models) are encapsulated within distinct packages under the Libraries section. Everything required in such a reseach environment is organized as mutually dependent calculation units with their calculation conditions congirued in the data update pipeline configuration.
Up to this point, a fresh envrionemnt is ready to support the comming resaerch needs.
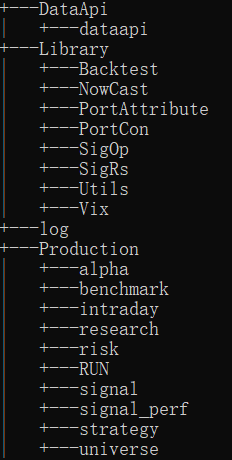
Some of the packages developed in this effort for reference: